Extracción de datos con Python renderizando javascript
Web Scraping es el proceso de extracción de información de sitios web para ser utilizado en otra aplicación. Las herramientas de scraping se utilizan para extraer información de los sitios web que no proporcionan una API para extraer los datos deseados. En los últimos años, el scraping web ha sido común con sitios web dinámicos, como los blogs de gestión de empresas, sitios de comercio electrónico, las redes sociales y foros.
A veces puede ser difícil de extraer datos de un sitio web que no tiene una misma estructura HTML sino que esta es dinámica. Aunque por suerte esto no es lo usual, y lo más común es que el HTML de un mismo dominio se repita su estructura por lo que es muy fácil de recorrer.
Extraer información de sitios web con Python es una forma eficaz de recopilar datos. Python es un lenguaje de programación potente que es fácil de aprender y puede recoger rápidamente los datos de sitios web. En este artículo te voy a mostrar una manera para scrapear datos con Python.
Que vamos a scrapear
Para este tutorial vamos a utilizar el entorno de prueba que he creado en ParaScrapear.com y concretamente en la página especifica que genera contenido con JavaScript.
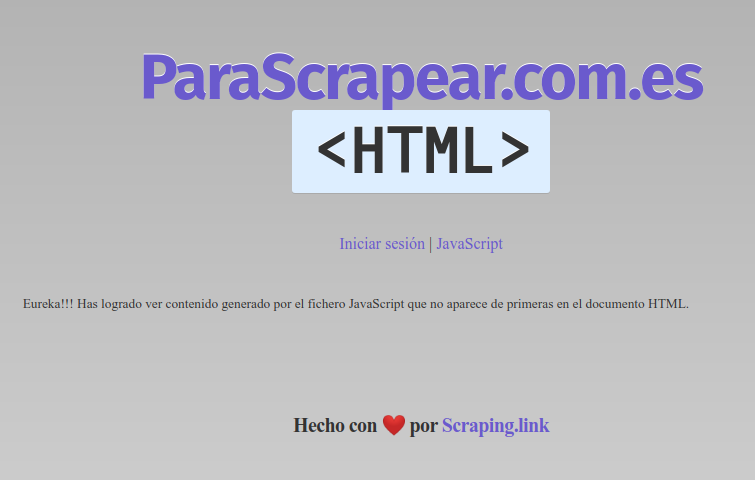
Pero si abrimos el código fuente
view-source:https://parascrapear.com/javascript
En realidad el texto del HTML que muestra en la etiqueta <div id=”javascript”> es:
Si ves esto NO tienes activado el JavaScript
en lugar de como se muestra en la captura
Eureka!!! Has logrado ver contenido generado por el fichero JavaScript que no aparece de primeras en el documento HTML.
Vamos a utilizar esta url para ver los pasos que necesitamos dar para renderizar el JS.
Requisitos para scrapear con Python
Necesitamos arrancar nuestro proyecto de python y la mejor manera es comenzar con las librerías básicas que se necesitan. Vamos a usar 2 librerías que son request y BeatufilSoup para comenzar. Por lo que vamos a utilizar el instalador de librerías de python que es pip
pip3 install requests
pip3 install beautifulsoup4
Una vez que tenemos estas librerías instaladas pasamos a crear nuestro script.
Comenzando el script de Python para scrapear
Vamos a escribir un primer script para ver cual es el resultado, lo guardaré en un fichero llamado scriptrequests.py. Si deseas conocer como funciona las librerias de requests y BeautifulSoup te recomiendo este artículo.
import requests
from bs4 import BeautifulSoup
resp = requests.get("https://parascrapear.com/javascript")
soup = BeautifulSoup(resp.text, "html.parser")
print(soup.find(id='javascript').text)
Al ejecutar este script el resultado es el siguiente:

Como podemos ver no ha renderizado el javascript, esto lo vamos a ver en el siguiente apartado como tenemos que hacerlo.
Renderizar el Javascript en Python
Para hacer el trabajo de renderizar ya hemos visto que la librería requests no es suficiente. lo que vamos a necesitar es utilizar la librería HTMLSession, con la que podremos interpretar el código javascript y devolver el HTML del resultado.
Antes de crear el script debemos instalar esta librería y en mi caso tuve que hacer un upgrade de requests con sudo para que me instalara todo correctamente te dejo las líneas que puse en mi terminal:
sudo pip3 install --upgrade requests
pip3 install requests-html
Crearemos este segundo script en el fichero llamado scripthtmlsession.py y este es el contenido:
from requests_html import HTMLSession
from bs4 import BeautifulSoup
session = HTMLSession()
resp = session.get("https://parascrapear.com/javascript")
resp.html.render()
soup = BeautifulSoup(resp.html.html, "html.parser")
print(soup.find(id='javascript').text)
Al ejecutar este script el resultado es el siguiente:

Como puedes ver en este caso si que ha funcionado correctamente y hemos logrado nuestro objetivo que era scrapear una web en la que parte de su contenido está creado por JavaScript.
 Grupo Discord
Grupo Discord